In the world of nutrition, mathematical models serve as powerful tools to study animal dietary requirements. These models play a pivotal role in helping us understand and predict precisely what animals need for optimal growth and development. In this post, we’ll explore a noteworthy mathematical model tailored for estimating amino acid requirements in pregnant sows—namely, the NRC (2012) gestating sow model. What makes this model particularly intriguing is a unique component: the enigmatic “time-dependent protein deposition.” This mysterious entity represents protein deposited by pregnant sows, yet its destination and functions remain unknown. Let’s investigate what the ‘time-dependent protein deposition’ is and how this may be an artifact of data interpretation.
The NRC (2012) gestating sow model
The National Research Council (NRC) which is the operating arm of the United States National Academies of Science, published a model in 2012 to determine optimal dietary protein and amino acid requirements for pregnant sows [1]. This model involves a series of calculations summarized as follows:
- It calculates the amount of protein retained by the animals during gestation. This estimation includes protein retention in various tissues such as lean tissue, placenta, uterus, mammary gland, and the growing fetus for each day of gestation.
- The model incorporates a factor to account for protein excretion, typically around 50%. This factor is then applied to calculate the overall protein requirement. For instance, if, on day 50 of gestation, the sow retains 70 g of protein, the model suggests providing 140 g in total. This is because 70 g will be retained, while the other 70 g will be excreted. The model conducts similar calculations for each essential amino acid.
Nevertheless, when calculating the protein retained in the different tissues (step 1 above), there was one protein pool that had no explanation, which was termed as the time-dependent protein deposition (figure 1).
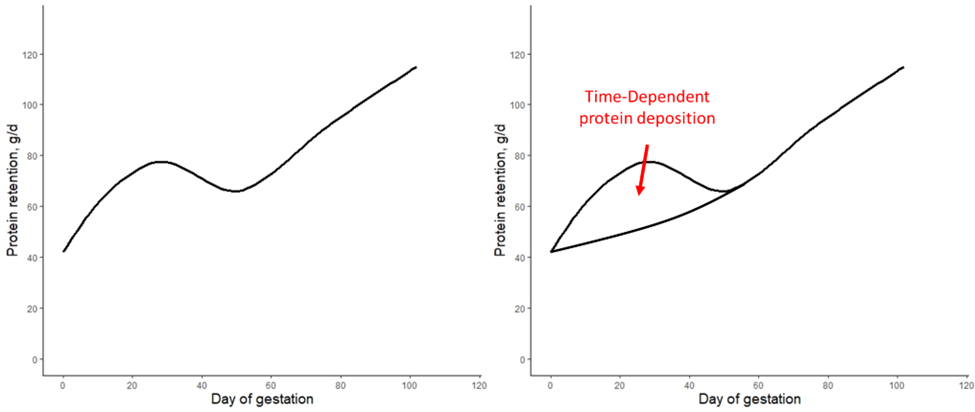
Figure 1. A. Simplified version of the protein deposition calculated by the NRC (2012) gestating sow model [1]. B. The protein retention is expected to increase across gestation, but there is some unexplained protein deposition pool termed as the time-dependent protein deposition.
What is the Time-dependent protein deposition?
The protein retention model in pregnant sows described above was developed based on a literature review performed by the NRC (2012) [1]. Nevertheless, there was no data available for the first 30 days of gestation, and assumptions had to be made. The NRC (2012) assumed reduced protein retention during the first days of gestation. As shown in the animation below, it seems that this assumption of reduced protein deposition during the first days of gestation caused the emergence of time-dependent protein deposition. When the assumption of reduced protein deposition at breeding is not considered, the relationship between the day of gestation and protein retention becomes quadratic.
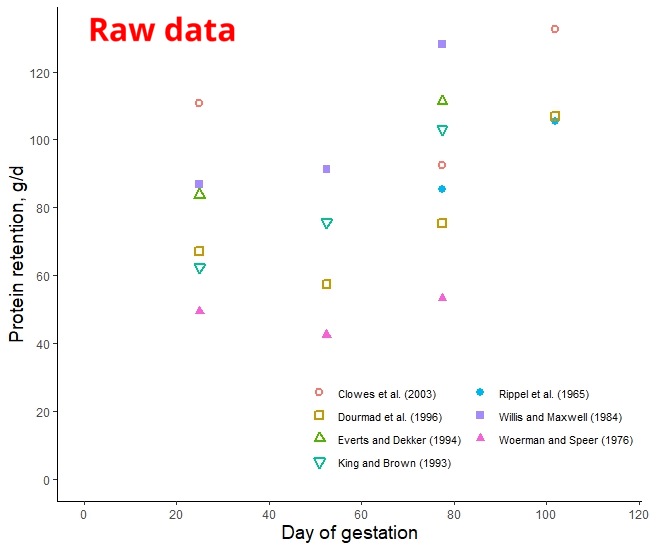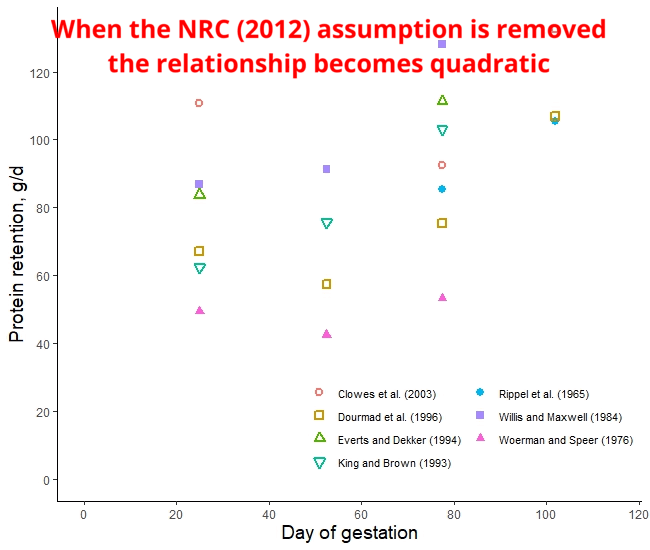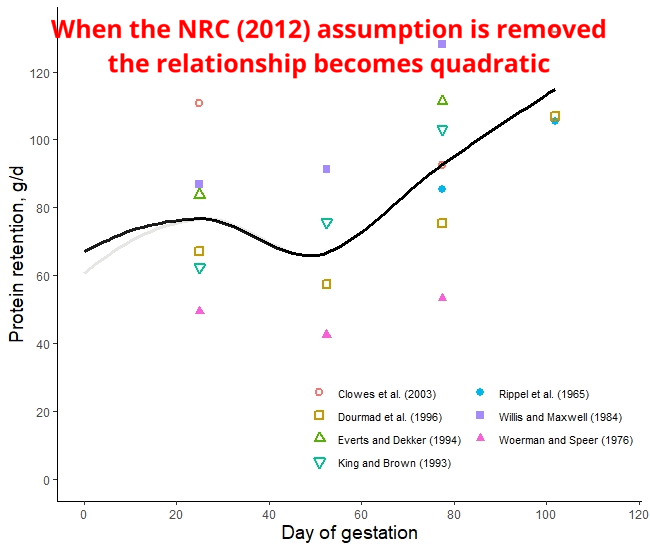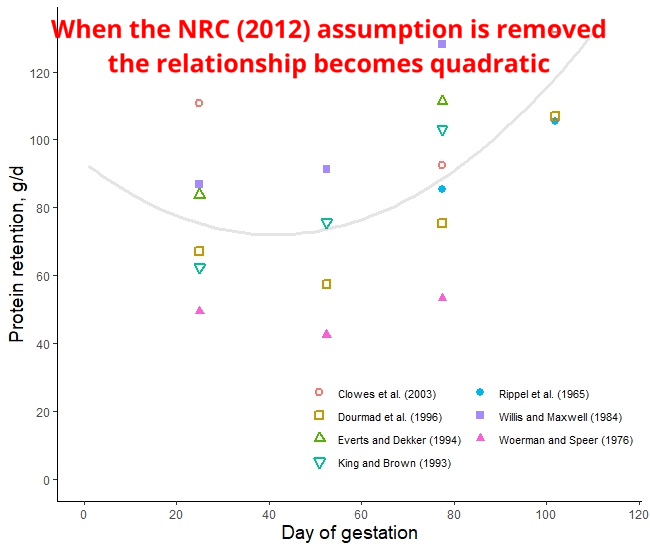
A similar assumption regarding amino acid requirements was made by both American and French researchers. The model used for estimating AA requirements in the NRC (2012) and the INRAE (French National Research Institute for Agriculture, Food, and Environment) differs only by 3% [2]. However, the amino acid requirements calculated by Brazilian researchers take a different approach. They do not rely on the assumption of reduced protein deposition during early gestation and, as a result, recommend increased AA intake levels during this period [3]. Which set of predictions is more accurate: the ones made by the Americans and the French or the Brazilians? This is a topic we will explore in a future post.
“The Strange Case of Time-Dependent Protein Deposition” is an illustrative example highlighting that scientific models, both mathematical and conceptual, are often built on assumptions due to limited or incomplete information. It underscores the importance of recognizing the extent to which scientific knowledge relies on these assumptions, ensuring that we remain cognizant of the possibility that some scientific claims may not be absolute “facts.” The realm of biology, in particular, is replete with analogous situations where certain scenarios remain unverified through empirical evidence. However, these scenarios are sometimes treated as established facts due to a lack of comprehension regarding the underlying mental, conceptual, and mathematical models.
It is crucial to acknowledge that we build upon the foundation laid by eminent scientists who developed these models, including the NRC (2012), INRAE models, and the Brazilian tables for Poultry and Swine. These researchers have made invaluable contributions to the field of science. Consequently, we bear the responsibility of advancing science further while respecting their pioneering efforts. However, one recommendation for future models is to explicitly articulate the underlying assumptions that form the bedrock of these models. This transparency will facilitate the work of future scientists as more data becomes available. Moreover, it will enable users to discern the conditions under which the model predictions may hold true and when they may not. This approach fosters a more informed and robust scientific community.
Thanks for reading, and I hope you found this post helpful!

Christian Ramirez-Camba
Ph.D. Animal Science; M.S. Data Science
1. NRC, Nutrient Requirements of Swine: Eleventh Revised Edition. 2012, Washington, DC: The National Academies Press. 420.
2. van Milgen, J., et al., InraPorc: a model and decision support tool for the nutrition of growing pigs. Animal Feed Science and Technology, 2008. 143(1-4): p. 387-405.
3. Ferreira, S., et al., Plane of nutrition during gestation affects reproductive performance and retention rate of hyperprolific sows under commercial conditions. Animal, 2021. 15(3): p. 100153.

Wonderfull doc Cristian congratulations for make readeable and understandable statistics. Big fan of the blog…