In today’s fast-paced world, we rely heavily on various modern tools and technologies to increase our productivity and make our daily tasks easier. While it’s not necessary to have a deep understanding of these tools’ inner workings to use them effectively, it’s essential to know their purpose. For instance, we don’t need to know mechanics to drive a car or understand the optimal degree of rotation in a washing machine to get our clothes clean. However, we know when it is appropriate to use each tool. Similarly, in data analytics, although we do not need to understand the complex mathematics behind statistical models, we must know when to use each method and what questions it can answer. Not comprehending which model is appropriate for our data may result in obtaining the correct answer to the incorrect question. To illustrate this point, let’s examine a fictional experiment using two distinct approaches: inferential statistics and predictive analytics.
Consider the analogy of identifying an animal from a blurry photograph. In this hypothetical scenario, let us assume that after conducting an experiment, we can confidently identify an eye in the photo with a high degree of certainty (P<0.05). This information alone is insufficient to determine the animal’s species. However, if we detect horns, udder, tail, and a brisket in the same photo, with no significant p-values (>0.05), we may still infer that the animal is a cow. In this example, under inferential statistics the conclusions would be based on the statistically significant finding of an eye, while the rest of the data would be more likely ignored. In contrast, under the predictive analytics approach, a model could be created to predict photos of cows, even if the variables considered are not statistically significant. Statistically significant variables do not always lead to accurate prediction of outcomes and nonsignificant variables often have important predictive power [1]. Thus, if under the predictive analytics approach we create a model based on the data from the blurry photo, and it reliably detects cows in new photos, we could use that predictive model to study the physiology of a cow.
If your objective was to study the system as a whole and not just the eye of a cow, then inferential statistics was likely the right answer to the wrong question in the previous analogy. In animal science research, we are frequently interested in testing the effects of a specific intervention on multiple variables such as animal growth, reproduction, physiology, etc. However, we may obtain non-significant variables with high predictive power, or variables that yielded low p-values by chance but have low predictive power. Consequently, we can use both inferential and predictive methods to answer various questions and extract as much information as possible from our study. However, animal science graduate programs have a tendency to emphasize inferential statistics as the primary (if not the only) methodology, resulting in a propensity to view every problem as an inferential one. As Abraham Maslow said “If the only tool you have is a hammer, it is tempting to treat everything as if it were a nail,”. Thus, If the goal is to broaden the animal sciences, researchers must be equipped with a comprehensive toolkit that includes more than a hammer or, for that matter, P-values.
Despite the fact that predictive analytics models are available for use in animal science research, they are not widely used. Nevertheless, there are studies that employ these novel methods. Here are some examples of studies that use a predictive analytics technique called Random Forest.
- Machine learning approaches for the prediction of lameness in dairy cows [2].
- Comparison of forecast models of production of dairy cows combining animal and diet parameters [3].
- Random forest modelling of milk yield of dairy cows under heat stress conditions [4].
The papers above do not seek to test hypotheses, but rather to predict future outcomes and identify good predictors, which may or may not be associated with low p-values. As a result, predictive analytics can result in a more efficient use of collected data by providing producers with a ready-to-implement method for predicting real-world outcomes. Predictive analytics is frequently referred to as Machine Learning or Artificial Intelligence because, as models improve their predictions with additional data, they are considered to learn. Although Machine Learning models may use complex math, they are not complex in principle, and are usually simple models modified for a different purpose. Simple linear regression, for example, can be used to infer relationships between variables or to classify different groups of observation (Figure 1).
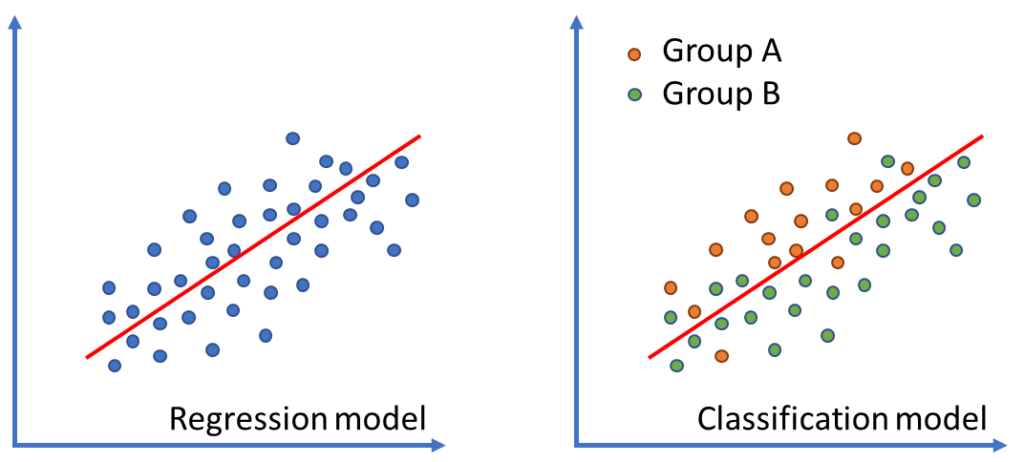
Figure 1. A linear regression model can be used to investigate the relationship between two variables (left) or to classify two groups based on how they respond to two different variables (right).
In figure 1, the P-value of the linear relationship is <0.01, indicating an interaction between variables. However, in the context of using this linear relationship for classification purposes, the P-value becomes irrelevant if the model fails to effectively split the two groups. In such a scenario, the accuracy of the classification model (correct predictions/total predictions) is a more informative measure than the P-value. The principle behind the two previous models in the image above is quite similar, and while both models can be considered machine learning algorithms, the classification model is considered a more advanced approach. In fact, the classification model in the figure above is considered to create a tree with two branches (group A and group B). The aforementioned artificial intelligence model called Random Forest is basically multiple regression lines that split the data in multiple branches and trees, thus creating a forest. This is by no means a comprehensive guide to regression trees; its sole purpose is to illustrate that complex artificial intelligence methods are founded on simple mathematical principles, which will be gradually explored in subsequent posts. It also serves to illustrate that there is a vast realm of statistics beyond p-values, which we will also explore in future posts.
Final Remarks
In most graduate programs in animal sciences, inferential statistics is the primary and often the only approach taught. However, multiple approaches can be used, including predictive analytics, Bayesian statistics, time series analysis, and deep learning. While these methodologies are commonly used in fields such as finance, healthcare, economics, and technology, animal sciences rely mostly on methods that are more than 100 years old. We are limiting our ability to fully understand the complexity of animal biology by failing to incorporate more advanced techniques. If we start incorporating these methodologies into our curricula today, it will take some time before we fully realize the benefits. Yet it is critical that we begin incorporating more advanced technologies into our graduate programs in order to produce higher-quality research and better understand our beloved animals.
Question for the reader:
- What can we do to improve data literacy among animal scientists at a faster rate?
Thanks for reading, and I hope you found this post helpful!
Christian Ramirez-Camba
References
1. Lo, A., et al., Why significant variables aren’t automatically good predictors. Proceedings of the National Academy of Sciences, 2015. 112(45): p. 13892-13897.
2. Shahinfar, S., et al., Machine learning approaches for the prediction of lameness in dairy cows. Animal, 2021. 15(11): p. 100391.
3. Nguyen, Q.T., et al., Comparison of forecast models of production of dairy cows combining animal and diet parameters. Computers and Electronics in Agriculture, 2020. 170: p. 105258.
4. Bovo, M., et al., Random forest modelling of milk yield of dairy cows under heat stress conditions. Animals, 2021. 11(5): p. 1305.